При использовании DC/OS в масштабируемых системах часто используются десятки и даже сотни серверов. По мере необходимости или в случае аварийных ситуаций узлы могут перезагружаться, при этом фреймворки DC/OS определяют недоступность задач и запускают их на других “живых” узлах или дожидаются, когда выключенные узлы снова будут online и перезапускают остановленные задачи на них.
Иногда это приводит к появлению задач в экзотических состояниях, которые не могут быть удалены как средствами UI, так и средствами DC/OS CLI.
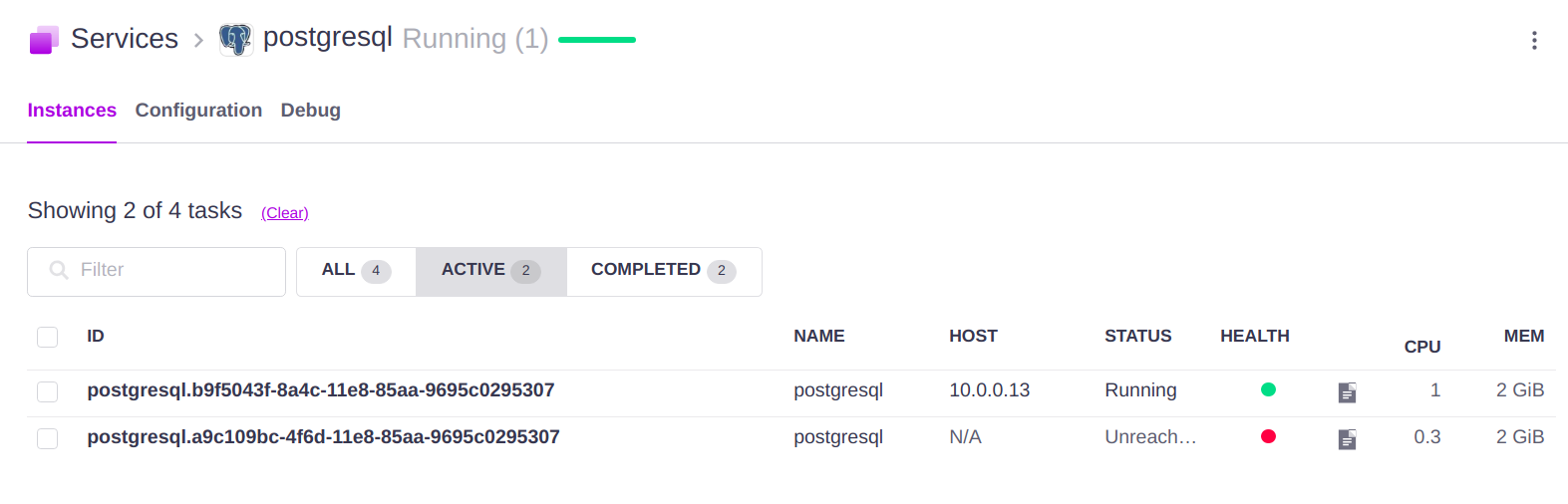
DC/OS построен поверх Apache Mesos, который использует Apache Zookeeper в качестве встроенной базы данных, поэтому мы предположили, что записи о таких задачах просто “залипли” в Zookeeper и их необходимо удалить. Однако, мы обнаружили, что таких записей в Zookeeper нет. Более того, DC/OS CLI тоже не видит данные записи, они присутствуют только в DC/OS REST API.
Мы предположили, что DC/OS просто кэширует где-то эти некорректные записи в рамках процесса Master. Для проверки гипотезы мы выполнили по очереди перезагрузку каждого master-процесса:
# systemctl restart dcos-mesos-master
Это привело к исчезновению данных записей из REST-интерфейса и UI. Стоит отметить, что данные задачи не утилизируют ресурсы и не представляют опасности, однако, “загрязняют” среду и могут ввести в заблуждение администраторов системы, поэтому их очистка полезна.
Помните, что перезагрузка процессов Master безопасна только в отказоустойчивом развертывании DC/OS, а в случае развертывания с единственным узлом в роли Master приведет к временной недоступности сервиса.
Читайте еще по этой теме:
Если вам понравился этот пост, поделитесь им с друзьями.