![]()
В данной статье мы рассмотрим архитектуру кластера HDFS 2.x с поддержкой высокой доступности (HA) и процесс развертывания кластера. HA-режим является основным режимом, применяемым на “боевых” кластерах Hadoop и должен использоваться во всех приложениях, к которым предъявляются требования высокой доступности. Современные кластерные оркестраторы, такие как DC/OS или Cloudera CDH предоставляют отказоустойчивый HDFS “из коробки”, однако, бывают случаи, когда требуется развернуть кластер HDFS без использования дополнительных инструментов. В этом случае, вам поможет данное руководство. Кроме того, в этой статье вы сможете узнать о том, как устроен HA-режим в Hadoop HDFS.
Порядок тем, освещенных в статье, следующий:
- Архитектура кластера HDFS HA
- Доступность узла NameNode
- Архитектура HA
- Реализация HA (JournalNode и разделяемое хранилище)
- Настройка HA (кворум JournalNode) на кластере Hadoop.
Введение
В Hadoop 2.x была представлена концепция кластера HA для решения проблемы единой точки отказа в Hadoop 1.х. Как известно, в архитектуре HDFS применяется топология Master/Slave, где узел NameNode выступает в качестве демона master и отвечает за управление другими узлами slave, которые называются DataNode. Этот единственный демон Master, или NameNode, и становится узким местом. Хотя добавление Secondary NameNode предотвратило потерю данных и сняло часть нагрузки с NameNode, это не решило проблему доступности узла.
Доступность NameNode
Если рассматривать стандартную конфигурацию кластера HDFS, становится ясно, что узел NameNode является единой точкой отказа. Это происходит потому, что в тот момент, когда NameNode становится недоступным, весь кластер становится недоступным до тех пор, пока NameNode не будет перезапущен, или не будет подключен новый узел.
Причинами отсутствия доступа к NameNode может быть:
- плановое мероприятие, например, технические работы по обновлению программного или аппаратного обеспечения;
- незапланированное событие, при котором NameNode стал недоступен по неизвестным причинам.
В любом из вышеуказанных случаев возникает время простоя, когда кластер HDFS использовать нельзя, что и становится проблемой.
Архитектура кластера HDFS HA
Давайте рассмотрим, как aрхитектура кластера HDFS HA решает проблему доступности узла NameNode. Архитектура кластера высокой доступности решает эту проблему путем возможности подключения двух узлов NameNode в режиме Active/Passive. Таким образом, в кластере высокой доступности есть два параллельно работающих узла NameNode:
- Active NameNode
- Standby/Passive NameNode.
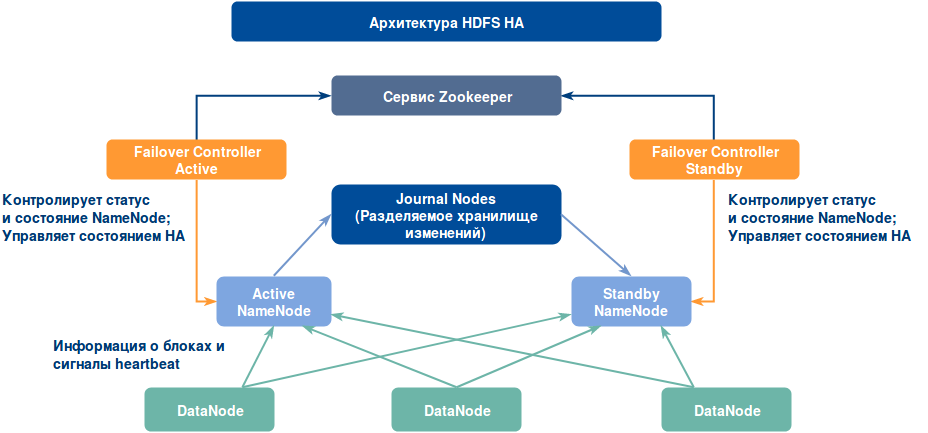
Если один узел NameNode выходит из строя, другой может взять на себя нагрузку и, следовательно, уменьшить время простоя кластера. Standby NameNode выступает в качестве резервного узла (в отличие от Secondary NameNode), который реализует обработку отказа в кластере Hadoop. Поэтому, при наличии StandbyNode можно реализовать автоматическую обработку отказа всякий раз при возникновении сбоев на NameNode (при внеплановых мероприятиях), или осуществить ручное переключение при проведении технических работ.
Существует две проблемы поддержания согласованности в кластере HDFS HA:
- Active и Standby NameNode’ы всегда должны быть синхронизированы друг с другом, т.е. должны содержать одни и те же метаданные. Это позволит обеспечить быструю обработку отказа и восстановить кластер Hadoop до того состояния, при котором произошел сбой.
- В один период времени должен быть активен только один узел NameNode, в противном случае наличие двух активных узлов NameNode приведет к повреждению данных. Данный тип сценария называется split-brain, когда кластер разделяется на два меньших кластера, каждый из которых считает себя активным. Во избежании подобных сценариев прибегают к процессу fencing. Fencing – это процесс, обеспечивающий активность только одного узла NameNode в определенный период времени.
Реализация архитектуры HA
Как вы уже поняли, в архитектуре HDFS HA есть два узла NameNode, запущенные одновременно. Реализация конфигурации с Active и Standby NameNode возможна одним из следующих способов:
- с помощью кворума узлов журналов (Journal Nodes);
- разделяемое хранилище с использованием NFS.
Давайте рассмотрим реализацию каждого из этих способов:
1. Использование кворума узлов журналов
Этот способ реализуется посредством группы сервисов, под названием Journal Node, и позволяет вести журналы изменений данных, необходимые в свою очередь для синхронизации Active NameNode и Standby NameNode друг с другом. Группа должна включать в себя как минимум три узла. Оптимальное количество узлов в группе можно расчитать по следующей формуле: при количестве Journal Node равном N система может справится с отказом (N-1)/2 узлов. Например, при подключении 3 Journal Nodes система продолжит работать при отказе одного узла ((3-1)/2).
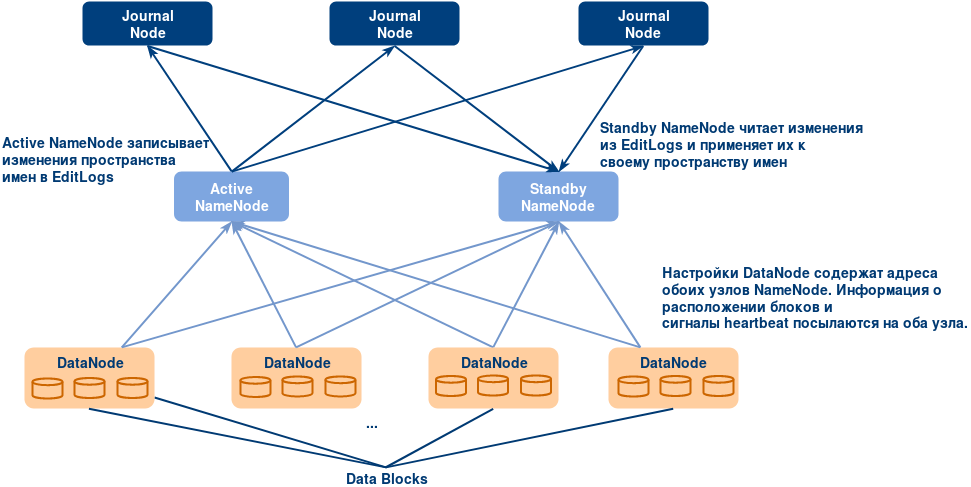
- Active и Standby NameNode синхронизируются друг с другом через отдельную группу узлов или демонов под называнием JournalNode. В JournalNode применяется кольцевая топология, в которой соединение между узлами образуют кольцо. JournalNode обрабатывает поступающий ему запрос и копирует информацию на другие узлы в кольце. Это обеспечивает отказоустойчивость в случае сбоя в работе JournalNode.
- Active NameNode отвечает за обновление EditLogs (метаданных) на узлах JournalNode. Резервный StandbyNode постоянно читает изменения, внесенные в EditLogs, и применяет их к своему пространству имен.
- При обработке отказа перед тем, как стать новым активным узлом NameNode, StandbyNode обновляет свои метаданные из JournalNodes. Это синхронизирует текущее состояние данных на узле с состоянием до возникновения сбоя.
- IP-адреса обоих NameNode доступны всем DataNode. Узлы DataNode посылают сигналы heartbeat и информацию о расположении блоков на оба узла NameNode. Это обеспечивает быструю обработку отказа (с меньшим время простоя), благодаря наличию на StandbyNode обновленных сведений о расположении блоков в кластере.
Fencing для NameNode:
Теперь, как уже было сказано ранее, очень важно обеспечить работу только одного активного узла NameNode в один период времени. Так, это свойство в кластере обеспечивается процессом fencing.
- Выполняют его узлы JournalNode, позволяя только одному узлу NameNode писать данные в один период времени.
- При обработке отказа Standby NameNode берет на себя ответственность писать в JournalNode’ы и блокирует активность других узлов NameNode.
- Таким образом, новый Active NameNode может спокойно выполнять свою работу.
2. Использование разделяемого хранилища
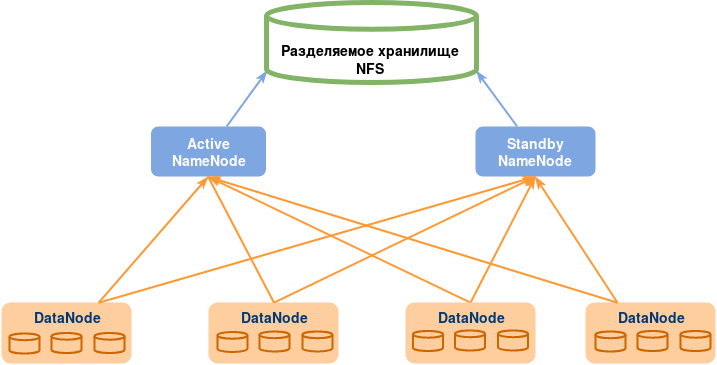
Standby NameNode и Active NameNode синхронизируются друг с другом с помощью разделяемого хранилища. Active NameNode записывает в EditLog, находящийся в этом разделяемом хранилище, любые изменения в пространстве имен. Standby NameNode читает изменения, внесенные в EditLogs, и применяет их к своему пространству имен.
В случае обработки отказа StandbyNode в первую очередь обновляет информацию о метаданных, используя EditLogs. После этого он берет на себя обязанности Active NameNode’ы. Это позволяет синхронизировать текущее состояние пространства имен с состоянием до обработки отказа.
Для избежания сценария split-brain администратору необходимо настроить как минимум один fencing метод.
Система может использовать ряд fencing методов, например, уничтожение процесса узла NameNode и лишение его доступа к директории разделяемого хранилища.
В крайнем случае, можно избавиться от ранее активного узла NameNode с помощью метода, известного как STONITH (акроним выражения “Shoot The Other Node In The Head” ), или “застрелить другой узел в голову”. STONITH использует специализированный метод для принудительного отключения машины NameNode.
Обработка отказа
Обработка отказа – это процедура, посредством которой при сбое системы управление передается резервной системе. Существует два вида обработки отказа:
- ручная обработка отказа – в этом случае мы вручную запускаем процесс обработки отказа. Данный способ применим для проведения плановых работ;
- автоматическая обработка отказа – в этом случае при сбое NameNode переключение производится автоматически.
Автоматическая обработка отказа
Службой, обеспечивающей автоматическую обработку отказа в кластере высокой доступности HDFS, является Apache Zookeeper. Он поддерживает небольшое количество координирующих данных, информирует клиентов об изменениях в этих данных, и следит за состоянием клиентов для определения сбоев в их работе. Zookeeper осуществляет:
- Выявление сбоев в работе — каждая машина NameNode в кластере поддерживает постоянное соединение с Zookeeper. Если машиина становится недоступна, сессия Zookeeper завершается, и он оповещает вторую NameNode о том, что необходимо запустить обработку отказа.
- Выбор Active NameNode — ZooKeeper предоставляет простой механизм выбора активного узла. При сбое в работе активного узла другой узел может применить исключающую блокировку и оповестить Zookeeper о том, что он станет следующим активным узлом.
Zookeeper Failover Controller (ZKFC) является клиентом Zookeeper, который также контролирует и управляет состоянием NameNode. ZKFC запускается на каждом узле NameNode и несет ответственность за периодический мониторинг состояния NameNode.
Установка и настройка кластера высокой доступности Hadoop с использованием кворума узлов журналов
Теперь, когда стало понятно, что обеспечивает высокую доступность кластера Hadoop, можно перейти к его установке. Чтобы развернуть кластер Hadoop HA, необходимо использовать по крайней мере 3 сервера Zookeeper, например, использовать Zookeeper на всех узлах кластера, где установлен Journal Node. Таким образом, полный перечень процессов для каждого узла представлен ниже.
- Active NameNode: Zookeeper, Zookeeper Failover Controller, JournalNode, NameNode
- Standby NameNode: Zookeeper, Zookeeper Failover Controller, JournalNode, NameNode
- DataNode 1: Zookeeper, JournalNode, DataNode
- DataNode 2-N: DataNode
Возможно выделить для узлов Journal Node отдельные узлы и установить Zookeeper только на них.
Ниже приводится инструкция для развертывания кластера Hadoop HA на ОС Ubuntu 16.04 (64-bit). Пароли машин необходидимо сохранить, так как они понадобятся при настройке доступа к машинам по SSH.
1. Установите Java и задайте имена узлов.
Для установки Java используйте команду:
sudo apt-get update -y && sudo apt-get -y install openjdk-8-jdk
Мы будем использовать следующие имена узлов:
|----------------------|----------------------
| Виртуальная машина | Имя узла
|----------------------|----------------------
| Active NameNode | nn1
| Standby NameNode | nn2
| DataNode | dn1
Установку и настройку кластера начнем с nn1. Поэтому следующие шаги будут выполняться на nn1.
2. Создайте каталог для хранения файлов конфигураций Hadoop, Zookeeper.
mkdir ha-cluster && cd ha-cluster/
3. В созданный каталог скачайте бинарный tar файл Zookeeper и Hadoop, извлеките файлы конфигураций.
На официальном сайте скачайте последнюю версию Zookeeper. Мы будем устанавливать Apache Zookeeper 3.4.13.
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
Разархивируйте zookeeper-3.4.14.tar.gz:
tar -xvf zookeeper-3.4.6.tar.gz

Скачайте бинарный tar-файл стабильного релиза Hadoop с сайта Apache Hadoop. Мы будем устанавливать Hadoop 2.7.7.
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.7/hadoop-2.7.7.tar.gz
Извлеките файлы Hadoop:
tar -xvf hadoop-2.7.7.tar.gz

4. Добавьте переменные окружения для Hadoop и Zookeeper в файл ~/.bashrc.
Редактируйте файл ~/.bashrc:
nano ~/.bashrc

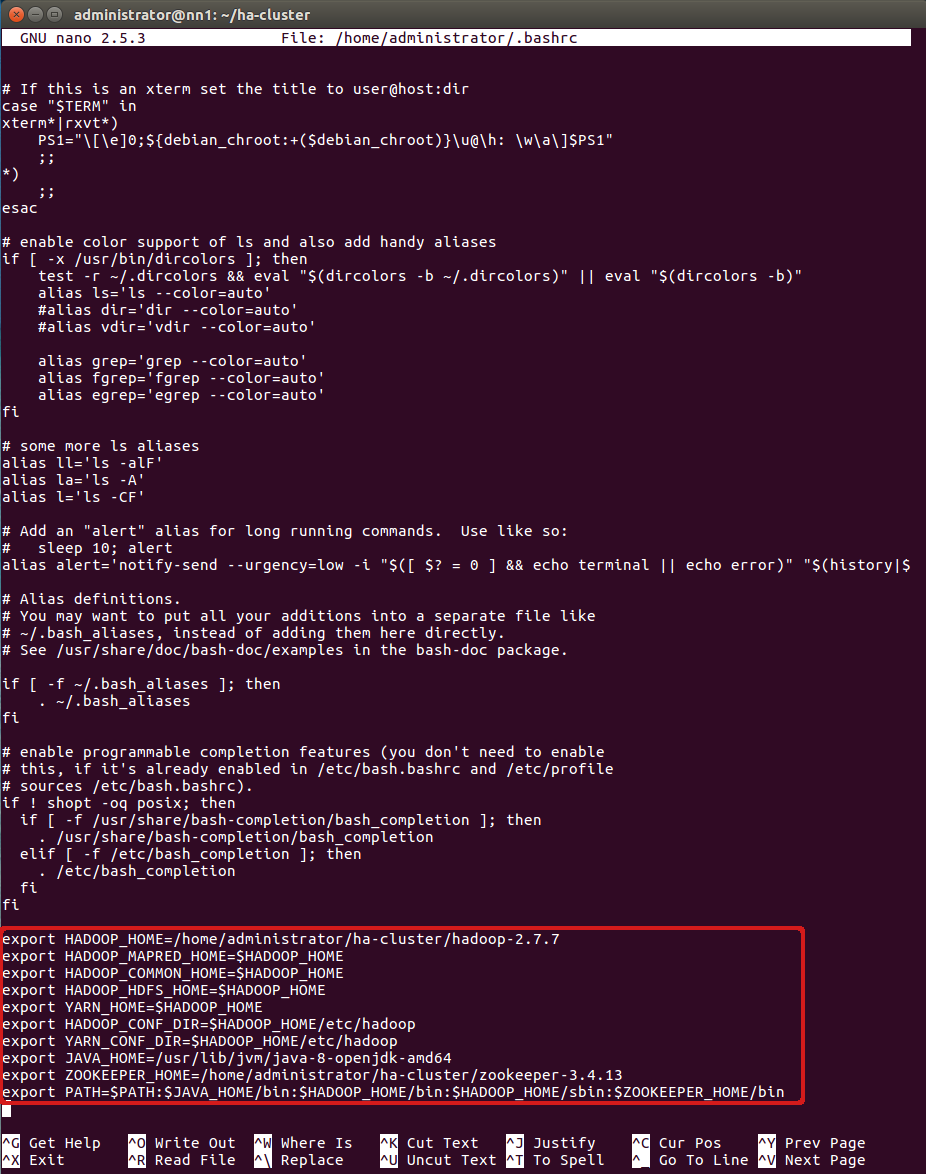
Добавьте переменные, указанные ниже:
export HADOOP_HOME=<путь к каталогу Hadoop>
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_HOME=<путь к каталогу Java>
export ZOOKEEPER_HOME=<путь к каталогу Zookeeper>
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
Примените изменения:
source ~/.bashrc

5. Активируйте SSH на всех узлах.
Сгенерируйте ключ SSH на всех узлах.
ssh-keygen -t rsa
Выполните команду на всех узлах.
Используйте все параметры по умолчанию.

Как только ключ SSH будет создан, вы получите открытый и закрытый ключи.
6. Необходимо скопировать открытый SSH-ключ на все узлы.
Для этого выполните следующие команды на каждом узле:
ssh-copy-id nn1
ssh-copy-id nn2
ssh-copy-id dn1
Удостоверьтесь, что любой узел доступен с любого другого узла без аутентификации.
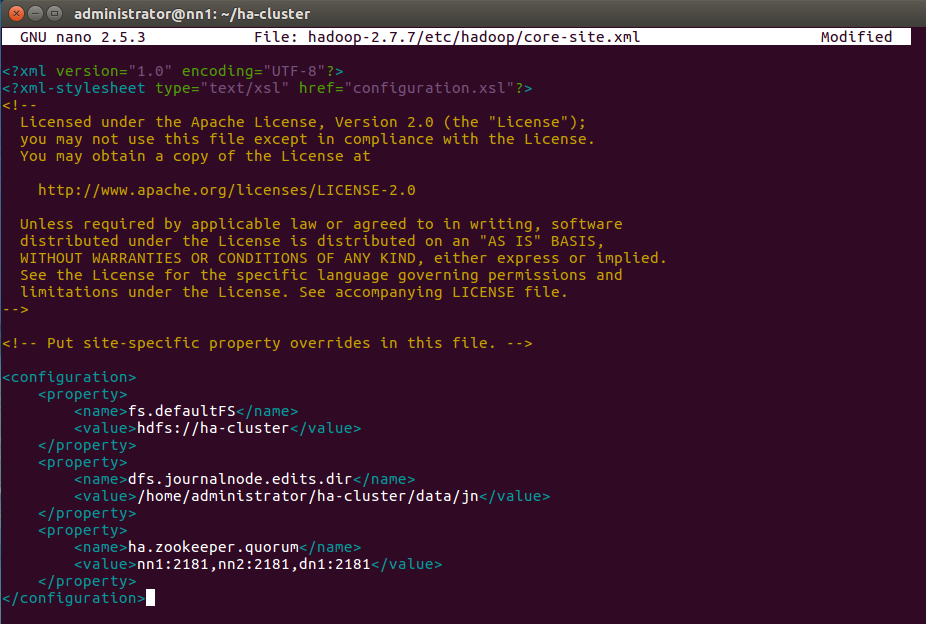
7. Редактируйте файл core-site.xml на nn1, указав свойства, указанные ниже.
nano hadoop-2.7.7/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ha-cluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/administrator/ha-cluster/data/jn</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>nn1:2181,nn2:2181,dn1:2181</value>
</property>
</configuration>
8. Редактируйте файл hdfs-site.xml на nn1, указав свойства, указанные ниже.
nano hadoop-2.7.7/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/administrator/ha-cluster/data/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ha-cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.ha-cluster</name>
<value>namenode1,namenode2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ha-cluster.namenode1</name>
<value>nn1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ha-cluster.namenode2</name>
<value>nn2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ha-cluster.namenode1</name>
<value>nn1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ha-cluster.namenode2</name>
<value>nn2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://nn1:8485;nn2:8485;dn1:8485/ha-cluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ha-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/administrator/.ssh/id_rsa</value>
</property>
</configuration>

9. Задайте настройки для Zookeeper.
Перейдите в каталог конфигураций Zookeeper на nn1:
cd zookeeper-3.4.13/conf
В каталоге conf находится файл zoo_sample.cfg. Создайте zoo.cfg, используя zoo_sample.cfg
cp zoo_sample.cfg zoo.cfg
Создайте каталог в любом месте для хранения данных Zookeeper’a:
mkdir <путь к каталогу, в котором вы будете хранить файлы Zookeeper'a>
Например, в нашем случае: mkdir -p ~/ha-cluster/data/zookeeper
Редактируйте файл zoo.cfg:
nano zoo.cfg
В файле zoo.cfg в dataDir укажите путь к каталогу, созданному на предыдущем шаге:
/home/administrator/ha-cluster/data/zookeeper
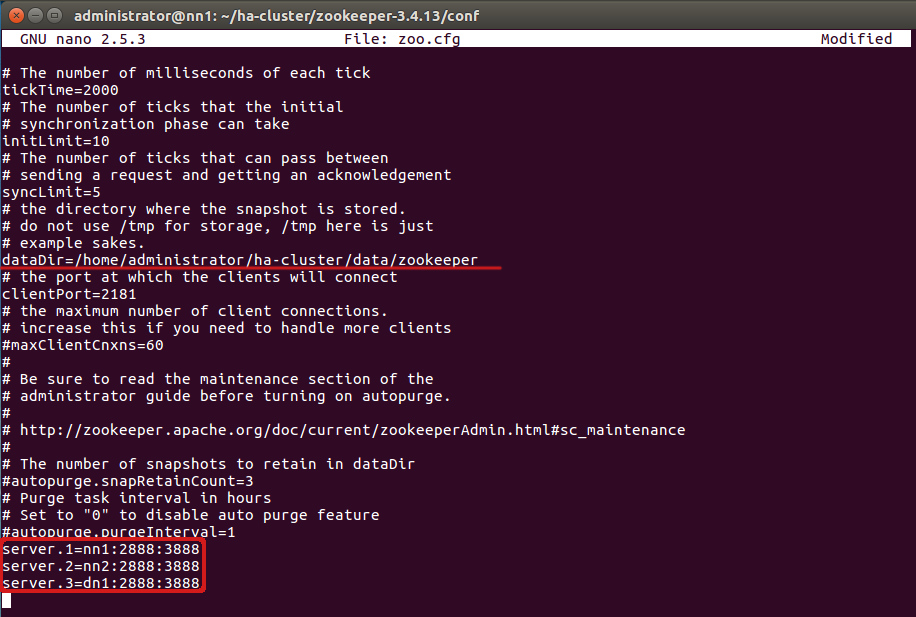
Добавьте ниже информацию об остальных узлах:
server.1=nn1.cluster.com:2888:3888
server.2=nn2.cluster.com:2888:3888
server.3=dn1.cluster.com:2888:3888
Создайте файл myid в каталоге для хранения данных Zookeper и редактируйте его, добавив число 1 в файл:
nano ~/ha-cluster/data/zookeeper/myid


Сохраните файл.
10. Теперь создайте каталог ha-cluster на остальных узлах (Standby NameNode nn2, DataNode dn1) и скопируйте в него каталоги data и Hadoop-2.7.7, Zookeeper-3.4.13, а также файл ~/.bashrc с помощью команды scp.
Для узла Standby NameNode nn2:
ssh administrator@nn2 "mkdir -p /home/administrator/ha-cluster"
scp -r ha-cluster/hadoop-2.7.7 ha-cluster/zookeeper-3.4.13 ha-cluster/data/ .bashrc administrator@nn2:/home/administrator/ha-cluster

Для узла DataNode dn1:
ssh administrator@dn1 "mkdir -p /home/administrator/ha-cluster"
scp -r ha-cluster/hadoop-2.7.7 ha-cluster/zookeeper-3.4.13 ha-cluster/data/ .bashrc administrator@dn1:/home/administrator/ha-cluster

11. На DataNode dn1 создайте каталог, в который будут сохраняться данные HDFS.
В нашем случае перейдем в ha-cluster:
cd ha-cluster
Cоздадим каталог datanode для хранения блоков:
mkdir data/datanode
Изменим права доступа к каталогу datanode:
chmod 755 data/datanode/
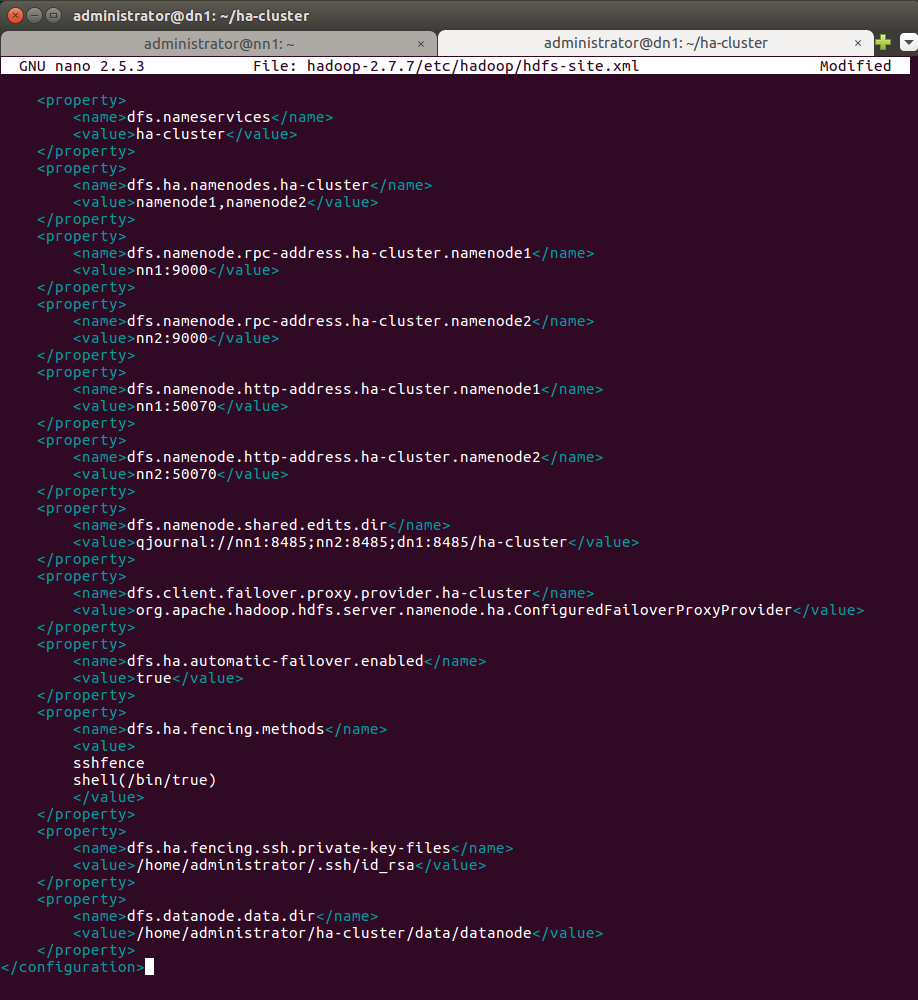
12. Редактируйте файл hdfs-site.xml, указав путь к каталогу datanode в dfs.datanode.data.dir.
Примечание: Оставьте все свойства, скопированные из Active NameNode nn1 и добавьте dfs.datanode.data.dir, как указано ниже.
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/administrator/ha-cluster/data/datanode</value>
</property>
13. На Standby NameNode nn2 перейдите в ha-cluster/data/zookeeper.
В нем редактируйте файл myid, заменив число 1 на число 2.
nano ~/ha-cluster/data/zookeeper/myid

Сохраните файл.
14. Аналогично, на DataNode dn1 перейдите в ha-cluster/data/zookeeper.
В нем редактируйте файл myid, заменив число 1 на число 3.
nano ~/ha-cluster/data/zookeeper/myid

Сохраните файл.
15. Запустите JournalNode на всех трех узлах.
$HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode
Выполните команда на каждом узле.

Проверьте с помощью команды jps, что JournalNode запустился на каждом узле.

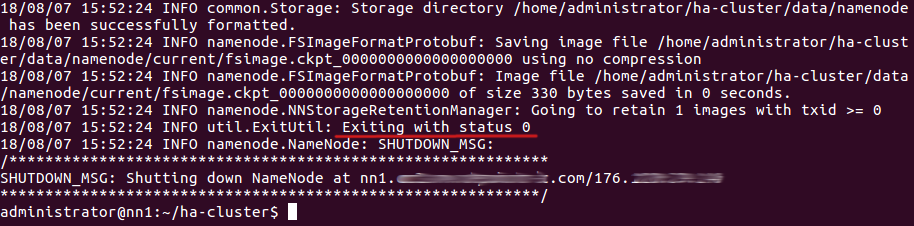
16. Форматируйте NameNode на nn1.
hdfs namenode -format
При успешном выполнении команды вы увидите:
Запустите процесс NameNode на Active NameNode nn1.
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
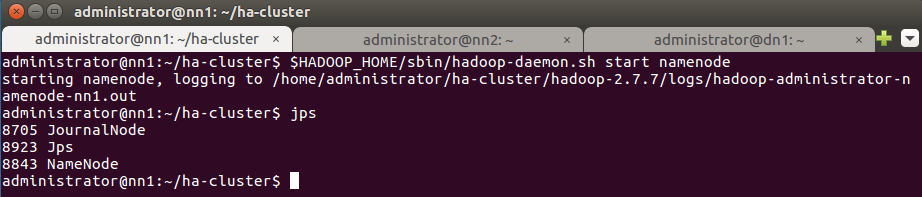
Проверьте с помощью команды jps, что на узле запущен NameNode.
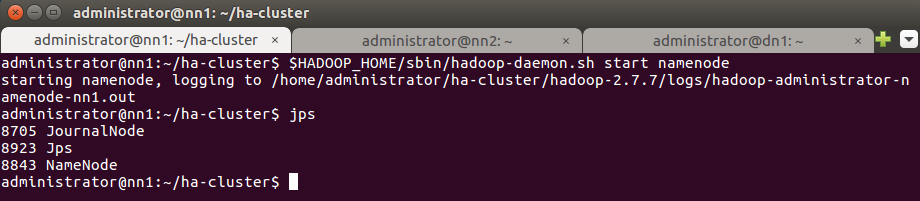
17. Скопируйте содержимое каталогов метаданных NameNode c Active NameNode nn1 на Standby NameNode nn2.
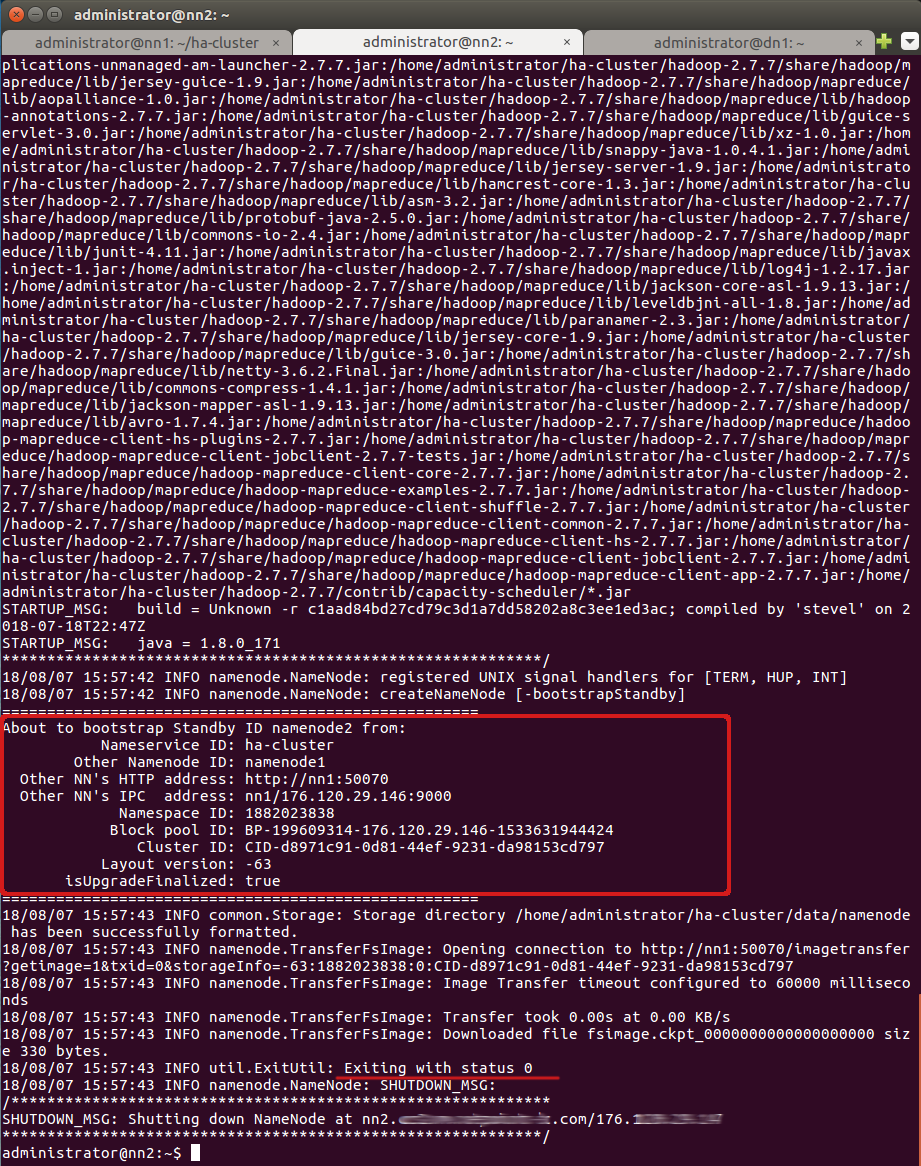
Для этого на Standby NameNode nn2 выполните следующую команду:
hdfs namenode -bootstrapStandby
При выполнении данной команды появится информация о том, с какого узла и какой директории копируются метаданные и успешно ли они копируются.
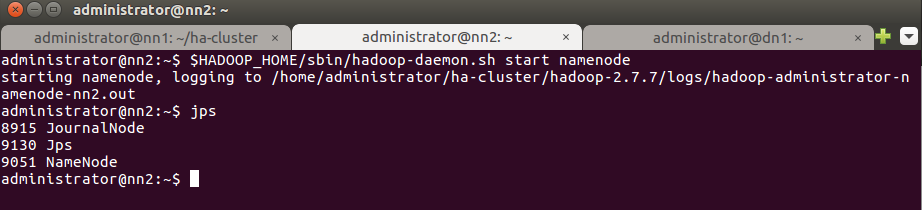
18. Запустите процесс NameNode на Standby NameNode nn2.
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
19. Теперь запустите Zookeeper на всех трех узлах.
$ZOOKEEPER_HOME/bin/zkServer.sh start
Выполнить запуск Zookeeper на всех узлах кластера.
После запуска Zookeeper введите команду jps. Убедитесь, что на всех узлах запущен QuorumPeerMain.
На изображении ниже показан результат выполнения команды на Active NameNode nn1:
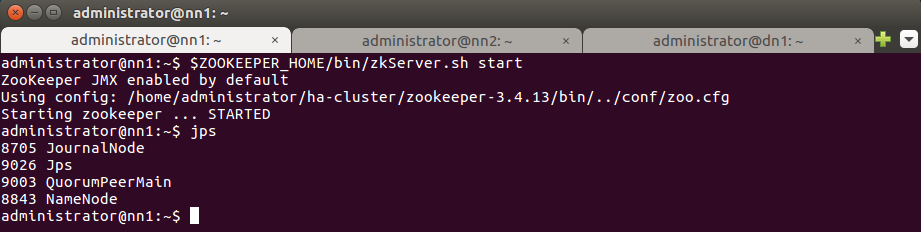
Аналогичный результат должен быть на Standby NameNode nn2 и на DataNode dn1.
20. Запустите демона DataNode на узле DataNode.
$HADOOP_HOME/sbin/hadoop-daemon.sh start datanode
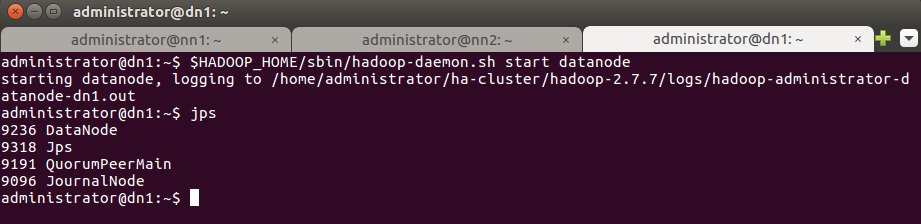
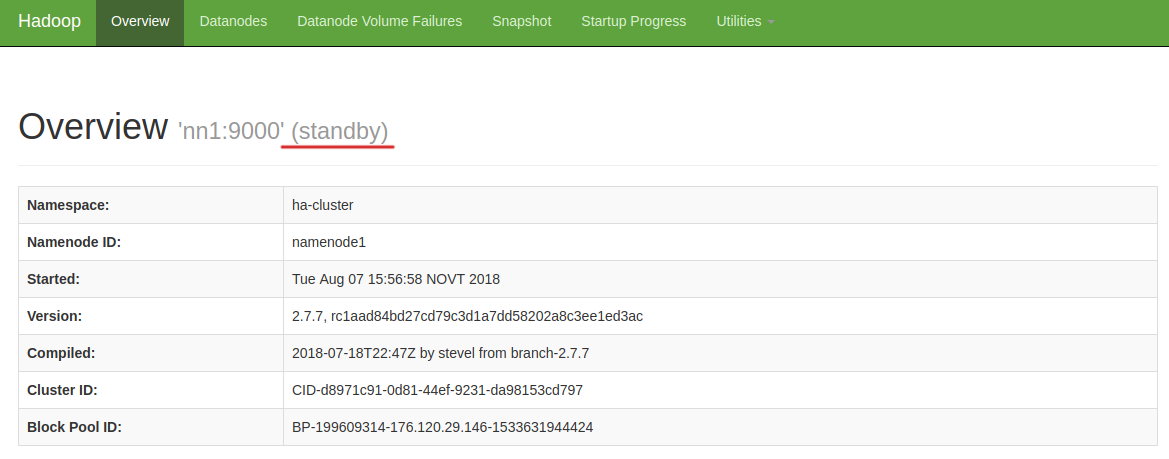
На данном этапе оба узла – nn1 и nn2 являются standby.
Статус узла nn1:
Статус узла nn2:
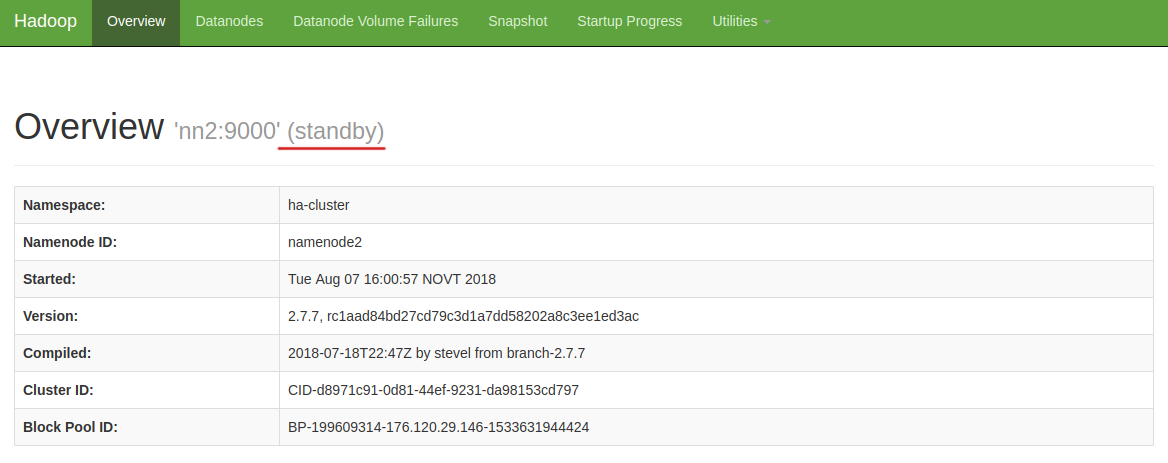
После выполнения следующего шага один из узлов станет active. Это зависит от того, на каком из узлов первым будет запущен Zookeeper Failover Controller. Мы будем запускать его сначала на nn1, затем на nn2. Таким образом, nn1 станет active, а nn2 – standby.
21. Запустите Zookeeper Failover Controller на nn1.
Сначала форматируйте Zookeeper Failover Controller:
hdfs zkfc -formatZK
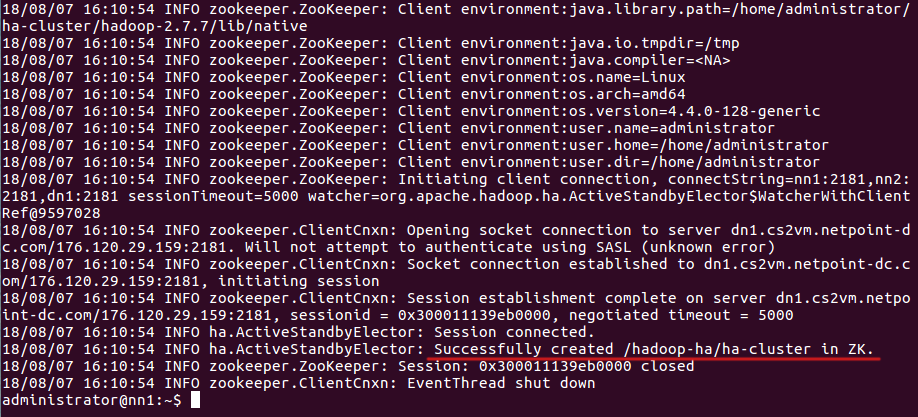
Затем запустите ZKFC на nn1:
$HADOOP_HOME/sbin/hadoop-daemon.sh start zkfc
Выполните команду jps для проверки процесса DFSZkFailoverController.
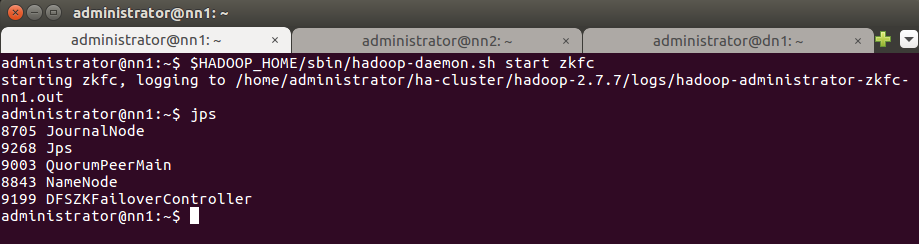
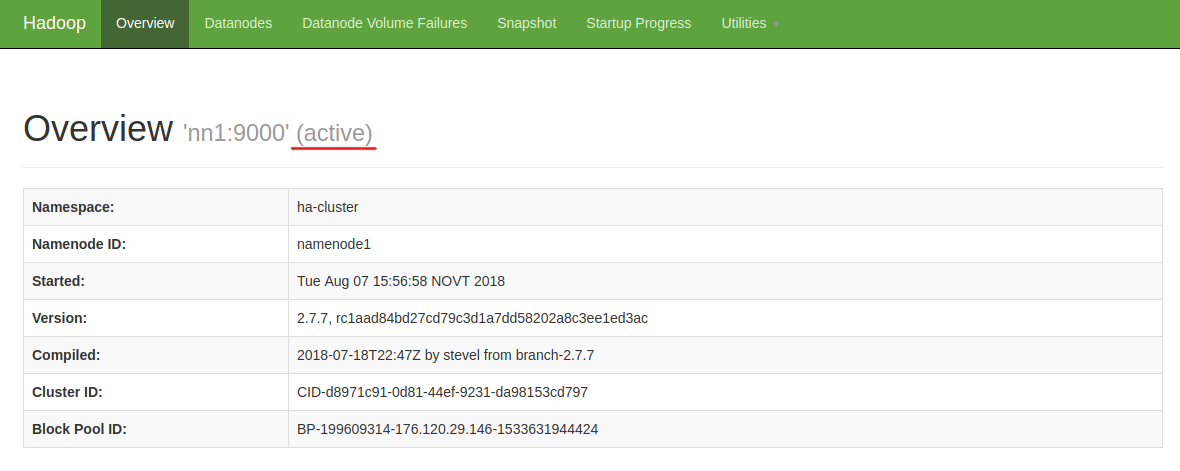
Проверьте статус узла через веб-браузер. Откройте веб-браузер и введите URL-адрес:
http://<IP адрес узла>:50070
Узел nn1 стал active:
Запустим Zookeeper Failover Controller на nn2:
$HADOOP_HOME/sbin/hadoop-daemon.sh start zkfc
Введите команду jps для проверки процесса DFSZkFailoverController.
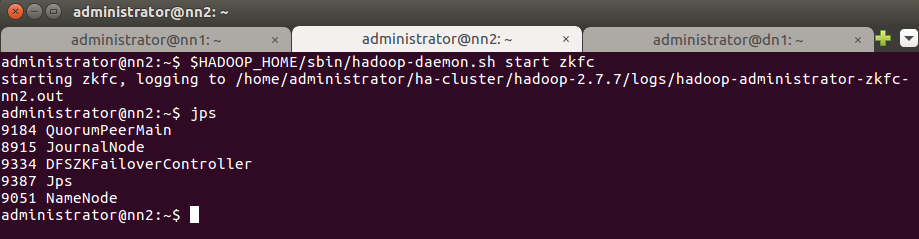
Проверьте статус узла через веб-браузер. Узел nn2 должен остаться standby.
Проверить, какой узел является Active, а какой – Standby, также можно с помощью команды:
hdfs haadmin -getServiceState <имя узла>
Например, для проверки статуса узла nn1 выполните: hdfs haadmin -getServiceState nn1
22. Теперь посмотрим, что произойдет, если Active NameNode (у нас это nn1) станет недоступен.
На Active NameNode nn1 остановите процесс NameNode, чтобы Standby NameNode nn2 стал активным:
sudo kill -9 <ID процесса NameNode>
ID процессов демонов можно получить с помощью команды jps:
jps
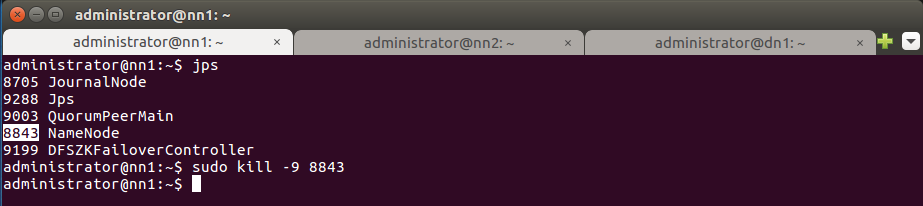
ID процесса Namenode – 8843, остановите NameNode на nn1:
sudo kill -9 8843
Проверьте статусы узлов через веб-браузер:
- Узел nn1 недоступен.
- Статус nn2 сменился на active:
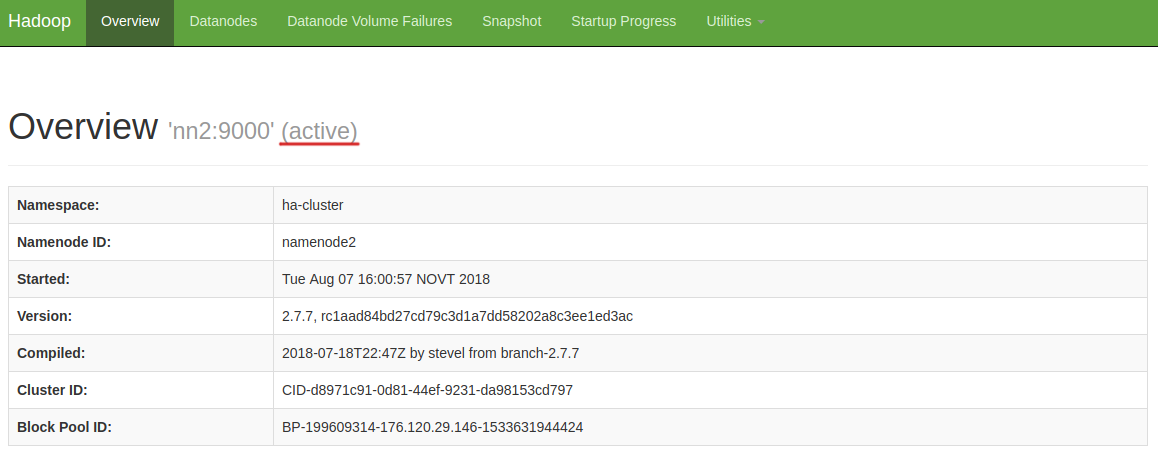
Период времени для обнаружения сбоя и переключения на доступный ресурс устанавливается настройкой ha.zookeeper.session-timeout.ms. По умолчанию он составляет 5 секунд. При возникновании проблем с переключением проверьте логи процессов zkfc и NameNode на том узле, который должен стать активным.
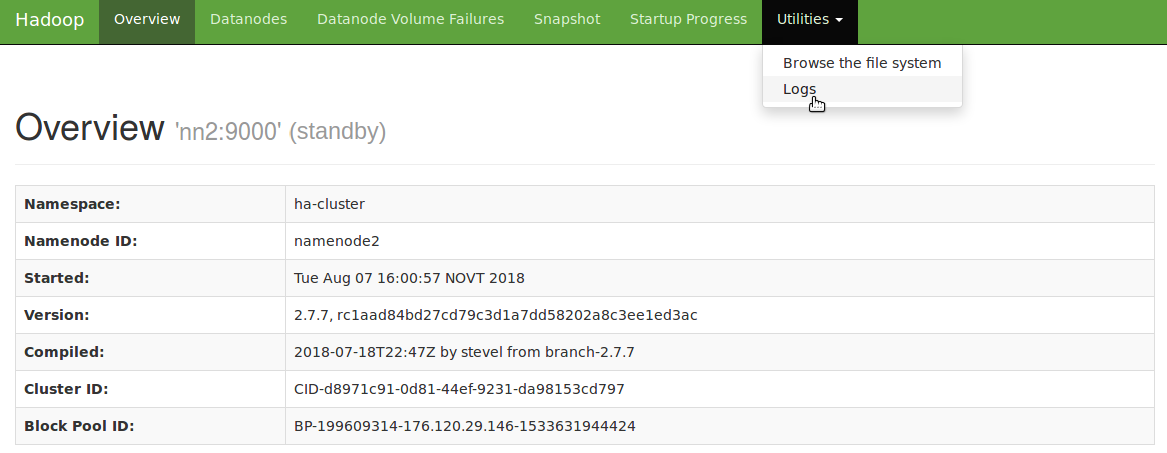
Выберите из списка файлы с расширением .log, содержащие в имени “zkfc” и “namenode”:
Снова запустим nn1, выполнив на нем команду:
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
Проверим статус узла через веб-браузер. Как и ожидалось, он сменился на standby:
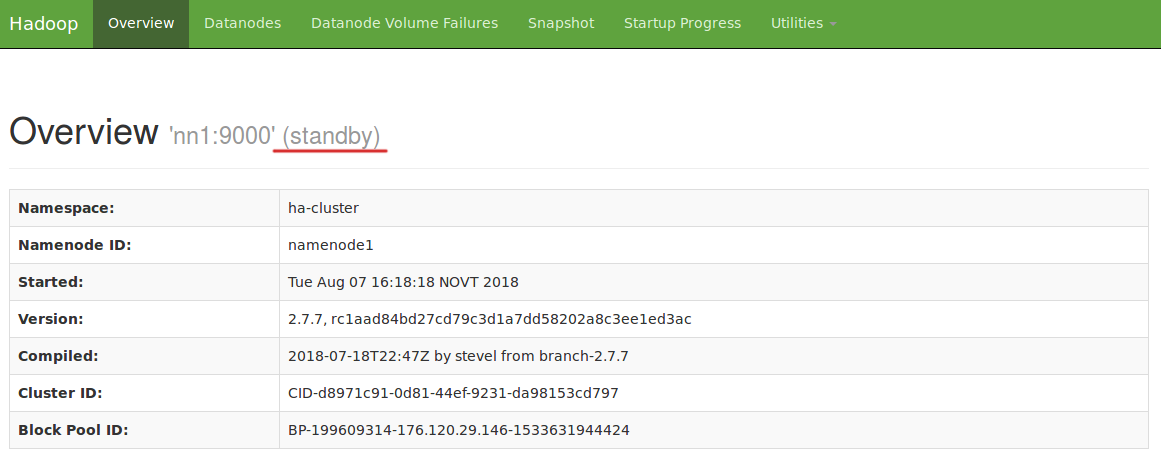
Поздравляем, вы успешно установили кластер HDFS в режиме высокой доступности.
Заключение
В рамках данной статьи мы рассмотрели архитектуру кластера Hadoop с поддержкой высокой доступности, а также процесс установки и настройки кластера Hadoop 2.7.7 c HDFS HA. Если вы обнаружили ошибку, вам непонятны некоторые инструкции, или есть предложения по улучшению статьи, будем рады, если вы свяжетесь с нами.
Если вам понравился этот пост, поделитесь им с друзьями.