За что мы любим InfluxDB? За то, что это выдающийся продукт, который позволяет работать с временными рядами легко; обеспечивает высокую производительность как на вставку, так и на извлечение данных; за то, что предлагает нам SQL-подобный язык запросов с удобными функциями обработки временных данных (например, производная от значений); за то, что его поддерживают удобные инструменты визуализации, такие как Grafana; за непрерывные запросы, позволяющие выполнять на лету агрегацию данных; а еще за то, что начать работать с InfluxDB можно в течение пары часов.
За что мы не любим InfluxDB? За то, что кластерное решение не является открытым. За масштабирование и отказоустойчивость необходимо платить, приобретая лицензию. В этом нет ничего плохого, однако, в концепции разработки программного обеспечения, основанной на свободном программном обеспечении, когда все инфраструктурные компоненты должны быть под открытыми лицензиями, места коммерческим продуктам не отводится. Соответственно, внедрение InfluxDB в критически важные места информационных систем невозможно.
В этой статье мы рассмотрим как с помощью дополнительного кластера Apache Kafka обеспечить масштабирование и отказоустойчивость InfluxDB для популярных вариантов использования, без необходимости приобретения коммерческой лицензии на кластер InfluxDB.
Стоит отметить, что вместо
Apache Kafkaв контексте этой статьи вы можете использовать любой другой брокер сообщений, но, поскольку наша компания часто используетKafka, а в продукте, где решение было применено,Kafkaуже присутствует, то мы решили использовать данную систему в этой статье. Вы же можете использоватьRabbitMQили другое решение, с которым вы знакомы. Однако,Kafkaобладает рядом преимуществ, которые помогают в рамках данного архитектурного решения.
Идея для написания данной статьи стала возможной после того, как мы решили проблему доступности сервера InfluxDB для одного из сервисов. Мы решили обобщить наш опыт, чтобы и другие разработчики ознакомились с успешным подходом к решению проблемы.
Системные требования
Начнем с того, что определим системные требования, которые важно учесть при внедрении этого архитектурного решения.
Изолированные читатели и писатели. В классических СУБД одни и те же агенты часто выступают и читателями и писателями. К счастью, в случае с TSDB это в большинстве случаев не так. В данной статье мы считаем, что часть процессов информационной системы – читатели, которые просто выполняют операции выборки над данными, другие же – писатели, которые только пишут данные. Между этим группами процессов может полностью отсутствовать связь или быть слабой. Важно то, что читатели не рассчитывают на производительность писателей, обработка данных происходит в полностью асинхронном режиме.
В том случае, если одни и те же агенты являются и читателями и писателями, причем над одними и теми же данными, подходы этой статьи не будут работать. Повторимся, что в случае TSDB такой вариант использования является редким.
Допустимость задержки обработки. Брокер сообщений может добавлять задержку в обработке от миллисекунд до секунд, в зависимости от его производительности, настроек и текущей нагрузки. Если такая задержка является критичной, подход использовать нельзя. С другой стороны, брокер сообщений может вам позволять более удобно работать с вставкой больших блоков записей в InfluxDB, что может повысить общую производительность.
Партиционируемость данных (только для задачи горизонтального масштабирования). Данные должны партиционироваться на группы – в идеальном случае, ряды данных одного объекта не связаны с рядами для других объектов. В более общем случае, все объекты можно разделить на подгруппы без связей между подгруппами.
Решаемые задачи
В рамках предлагаемой архитектуры мы будем решать следующие задачи:
- повышение отказоустойчивости, производительности чтения данных из
InfluxDBза счет дублирования данных – кластер высокой доступности; - повышение производительности чтения и записи данных за счет партиционирования (шардинга) – кластер высокой производительности;
- гибридное решение высокой производительности и доступности.
Архитектура высокой доступности
Эта архитектура является наиболее простой. Ее схема приведена на рисунке:
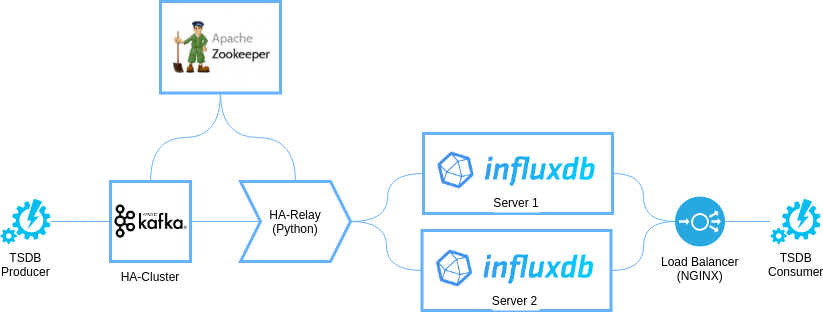
При этом с точки зрения размещения компонентов на физических или виртуальных узлах архитектура будет представлена трехузловой конфигурацией, изображенной на рисунке:
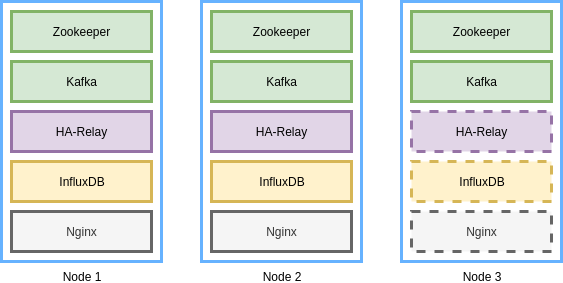
Проще всего развернуть данную топологию с использованием Docker – в режиме Swarm или в некластерном варианте. Однако, вы можете использовать и развертывание приложений без контейнеров и в Kubernetes, OpenShift или DC/OS. Компоненты с контурами в форме пунктирных линий являются опциональными, и в минимальной конфигурации могут быть исключены, однако, если вы предпочитаете максимально унифицированное развертывание, будет проще сразу добавить их в ваши сценарии Ansible, Chef или другие средства автоматизированного конфигурирования.
Основа архитектуры
В основе архитектуры лежит отказоустойчивый кластер, построенный на базе Apache Kafka и Apache Zookeeper – это два широкоизвестных и надежных программных компонента, которые позволят нашей архитектуре быть высоконадежной и производительной.
Apache Zookeeper. Этот компонент будет использоваться непосредственно Kafka, поскольку необходим этому программному обеспечению для нормальной работы. Кроме того, Zookeeper будет использоваться в качестве сервиса распределенных блокировок для HA-Relay – чтобы избежать многократной записи одних и тех же данных в InfluxDB нам необходимо обеспечить работу только одного сервиса HA-Relay в каждый момент времени. Для этого мы можем использовать рецепт блокировки.
Apache Kafka. В нашей архитектуре Kafka выполняет функцию высоконадежного и высокопроизводительного буфера FIFO для преднакопления записей временных рядов, которые будут загружены в InfluxDB. Как мы замечали ранее, вместо Kafka можно использовать другой сервис очередей, а так же полностью его исключить, однако мы видим в использовании Kafka уникальные возможности для предложенной архитектуры:
- буферизацию данных перед загрузкой в
InfluxDB; - возможность повторной загрузки данных в случае частичного или полного разрушения хранилища
InfluxDB; - поддержку транзакционной загрузки данных из агента в буфер (с помощью транзакций или идемпотентной загрузки Kafka) и далее – идемпотентно из буфера в
InfluxDBс помощью меток времени записейKafka.
В данной топологии вам, вероятнее всего, будет достаточно использовать в
Kafkaодин топик с трехкратной репликацией.
Устройство HA-Relay
Этот элемент архитектуры реализуется с помощью удобного для вас языка программирования. Его задача – читать данные из Kafka и перекладывать их в несколько несвязанных баз InfluxDB, при этом важно обеспечить следующие характеристики:
- недублируемость данных (в кластере работает только один
HA-Relayв каждый момент времени), это можно обеспечить с помощью рецепта блокировкиZookeeper; - данные, читаемые из
Kafkaзагружаться блоками, чтобы минимизировать нагрузку наInfluxDB; - время для каждой записи
InfluxDBустанавливается временем из сообщенияKafka, что позволяет избежать искажение времени, особенно в случае отставанияHA-Relay; - для каждого элемента данных, который будет добавляться в
InfluxDBзаполняются дополнительные поля, полученные изApache Kafka:topic,partition,offset,timestamp, это позволит в случае повторной загрузки уже загруженных записей просто перезаписать их вInfluxDB, а не создавать дубликаты.
Реализовав HA-Relay с поддержкой вышеуказанных требований вы можете быть уверены, что данные в InfluxDB будут в конечном итоге консистентыми (eventually consistent). В определенные моменты времени система может показывать лаг обработки (задержку), но данные не будут содержать неверных временных меток и пропусков (за исключением периода синхронизации).
Синхронизация серверов после отказа
Если один из серверов InfluxDB выходит из строя, то возникает ситуация, когда данные продолжают записываться только на оставшиеся сервера, а на отказавшем сервере они будут отсутствовать. После старта сервер будет возвращать некорретные данные. Для синхронизации требуется реализовать отдельный протокол, который будет обрабатывать данный случай особым образом.
Протокол должен учитывать следующие моменты:
- до завершения синхронизации отстающий сервер
InfluxDBдолжен быть недоступен для запроса данных – его необходимо отключить из балансировкиNginx, что можно сделать как с помощьюIptables, так и с помощью реконфигурированияNginx; - синхронизация должна включать загрузку данных, начиная с момента отказа сервера
InfluxDBи до текущего смещения, сохраненногоKafkaвZookeeperна момент запуска синхронизации.
Для синхронизации удобно использовать одноразово запускаемое приложение, которое будет выполнять данную процедуру.
Балансировка нагрузки через Nginx
InfluxDB использует протокол, основанный на HTTP. Это значит, что вы можете использовать Nginx для организации балансировки нагрузки между серверами InfluxDB, что позволит добиться как балансировки трафика для повышения производительности приложений, так и для обеспечения отказоустойчивости при выходе одного из серверов из строя.
Масштабируемая отказоустойчивая архитектура
Второй вариант архитектуры – масштабируемая, отказоустойчивая архитектура. Это более сложная топология, которая основывается на предыдущей архитектуре. Архитектурная диаграмма представлена на следующем изображении:
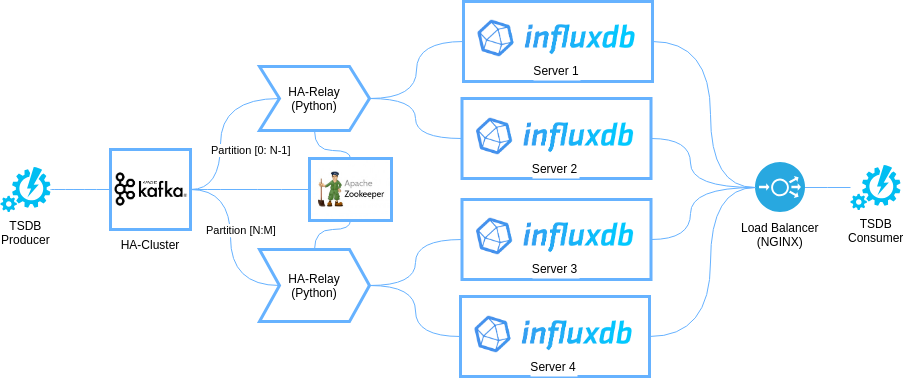
Масштабирование основывается на шардинге данных, который выполняется с помощью разбиения всего множества данных на непересекающиеся группы и применение к ключевым полям алгоритма хэширования, который отображает все множество ключей объектов в множество партиций Kafka. В этой архитектуре мы создаем топик Kafka с набором партиций, количество которых отражает ожидания по производительности – по одной партиции на каждый шард InfluxDB. Каждый шард может быть отказоустойчивым – тогда он состоит из двух серверов InfluxDB, которые реплицируют друг друга.
Устройство HA-Relay
В этой архитектуре HA-Relay оперирует не над всеми партициями, а только над выделенными ему, что позволяет обеспечить линейное масштабирование нагрузки. Вы просто добавляете по одному HA-Relay и паре серверов InfluxDB на каждую партицию и шард.
Устройство балансировщика Nginx
Для успешной реализации распределения нагрузки в рамках данной архитектуры только сервера Nginx будет недостаточно. Вам придется заглядывать внутрь запросов и понимать над какими объектами они будут выполняться для того, чтобы маршрутизировать их на серверы, которые хранят требуемые объекты. Для этого вы можете использовать микросервис, который обладает полной информацией о методе хэширования, используемом для распределения объектов, а в балансировщике Nginx использовать схему доступа к Influx вида http://server:8XXX, где XXX – номер партиции, например 001.
Ограничения
В этой архитектуре вы не сможете использовать запросы, в которых одновременно используются объекты с разных шардов. Вам придется реализовать дальнейшее редуцирование на уровне приложения. Как частный случай этого ограничения, вы не сможете для таких запросов использовать функциональность существующих инструментов, таких как Grafana, если они выполняют операции, действие которых распространяется на все множество данных, а не только на данные, расположенные в одном из шардов.
Заключение
Мы рассмотрели две практических архитектуры, которые позволяют значительно повысить применимость InfluxDB в высокодоступных системах, использующих только компоненты с открытым исходным кодом. Применимость этих архитектур широка, однако, их использование сопряжено с дополнительными инженерными решениями, которые требуют отдельную реализацию и инструменты управления.
При внедрении данной архитектуры необходимо учесть все требования к системе, поскольку во многих случаях вы можете столкнуться с ограничениями, которые препятствуют внедрению описанного решения.
Если вам понравилась статья, поделитесь ей с друзьями.