Бизнес-системы осуществляют сбор и обработку большого количества данных, объем которых в долгосрочном периоде может измеряться терабайтами и петабайтами. Накопление данных преследует разные цели: в одном случае они используются для увеличения объемов продаж и глубокой аналитики; в другом случае накопление данных может быть мотивировано индустриальными практиками.
На стадии проектирования систем, которые оперируют большими объемами данных, ключевой вопрос – выбор хранилища данных, пригодного как для хранения, так и для оперативной обработки этих данных. Несмотря на то, что в индустрии существуют решения, которые позиционируются как универсальные, часто на этапе анализа эффективности выполнения требуемых бизнес-процессами операций приводит к тому, что хранилище отбрасывается как неэффективное.
В рамках статьи мы рассматриваем использование СУБД Yandex ClickHouse для решения задачи доступа к аналитической информации аккаунтинга.
Система учета ресурсов и требования к ней
Для нашего продукта, предназначенного для управления облачными средами на базе платформы CloudStack, необходимо было спроектировать и реализовать систему, которая позволила бы вести учет затрат ресурсов облака с высокой точностью. На данном этапе для продукта уже реализован сервис, который позволяет вести детальный учет использованных ресурсов по каждому пользователю облака за предшествующую минуту и сохраняет результаты аккаунтинга в виде снимка RocksDB, отражающего состояние облака за данную минуту.
В рамках требований предполагается, что в системе будет действовать до 10 000 пользователей, которые будут генерировать до 100 000 000 записей аккаунтинга в сутки – 1 440 минутных срезов состояния для 10 000 пользователей, у каждого из которых имеется в среднем 9-10 измеряемых ресурсов. Ожидается, что одновременно в систему может поступать от 10 до 100 сложных запросов аналитики со стороны финансового биллинга и пользовательского UI.
Общая схема архитектуры представлена на рисунке:
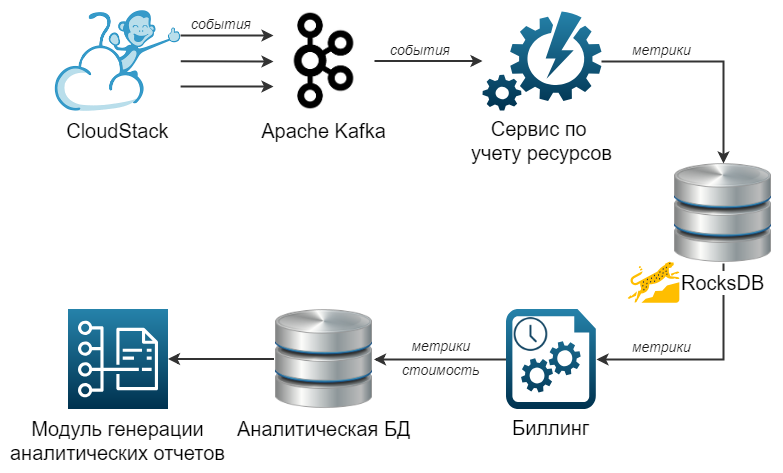
Сценарии использования
Необходимо заметить, что в рамках данного проекта мы реализуем не финансовый, а промежуточный биллинг, производящий универсальный подсчет в условных единицах, которые далее конвертируются финансовым биллингом в затраты по курсам конвертации, скидкам и тарифным планам.
Для соответствия системы биллинга поставленным целям требуется выполнение следующих сценариев:
- Расчет затрат для каждого пользователя системы в текущем периоде биллинга для списаний средств с баланса.
- Расчет затрат определенного пользователя за произвольный период времени
- A. агрегированно для всех ресурсных элементов, принадлежащих определенной метрике;
- B. по отдельности для каждого ресурсного элемента, относящегося к метрике.
Критерии для выбора базы данных
Исходя из обозначенных сценариев, мы сформировали критерии выбора аналитической базы данных:
- решение должно быть открытым;
- поддержка атомарного добавления больших объёмов данных;
- горизонтальное масштабирование и репликация за счет добавления новых узлов;
- решение должно быть предназначено для хранения и обработки большого количества данных (более 100 млн новых записей за сутки);
- возможность агрегирования данных.
Кроме того, мы определили ряд требований к производительности решения:
- добавление одного батча данных, содержащего до 1 млн записей, должно осуществляться не более 1 минуты;
- при доступе к данным обработка одного запроса должна осуществляться не более 1 сек;
- возможность обработки 50 конкурентных запросов за 1 секунду.
Заявленная производительность должна достигаться на сервере доступной нам конфигурации для данных, сгенерированных для 14-месячного периода эксплуатации:

Характеристики ClickHouse
У нас уже был опыт применения ClickHouse в похожем проекте, поэтому, убедившись в соответствии требованиям, мы решили провести тестирование этой СУБД для целей данного проекта.
ClickHouse является аналитической базой данных с открытым кодом, которая разработана и успешно используется корпорацией Яндекс для обработки данных, объем которых исчисляется петабайтами.
ClickHouse имеет следующие свойства, которые делают ее потенциально применимой в данном проекте:
- колоночная база данных, которая позволяет эффективно делать сложные выборки на больших таблицах;
- поддержка декларативного языка запросов на основе SQL;
- open-source под лицензией Apache 2.0;
- поддержка репликации и шардирования для возможности масштабирования и обеспечения отказоустойчивости.
Для оценки ClickHouse мы провели тестирование производительности по описанным выше сценариям.
Подготовка к тестированию
Исходя из доступных нам вычислительных ресурсов и требований к тестированию, были сгенерированы тестовые данные, которые отражают работу 10 тысяч пользователей за период с 2017-01-01 по 2018-02-28 включительно. При этом предполагалось, что у каждого пользователя есть в наличии в среднем по 9-10 учетных единиц. В итоге получили 64,5 млрд записей, занимающих 1,3 ТБ данных.
Развертывание и донастройка ClickHouse
Для проведения тестирования была выбрана база данных ClickHouse версии 19.1.6. Для её установки мы использовали вариант установки и запуска из Docker-образа:
docker run -d --name clickhouse \
--ulimit nofile=262144:262144 \
-p 8123:8123 -p 9000:9000 \
-v $(pwd)/clickhouse/users.xml:/etc/clickhouse-server/users.xml \
-v $(pwd)/clickhouse/config.xml:/etc/clickhouse-server/config.xml \
yandex/clickhouse-server:19.1.6
где
- users.xml – файл, содержащий информацию о пользователях;
- config.xml – конфигурационный файл.
Учитывая требования к производительности, а также особенности рассматриваемых сценариев, настройки ClickHouse, используемые по умолчанию, были изменены следующим образом:
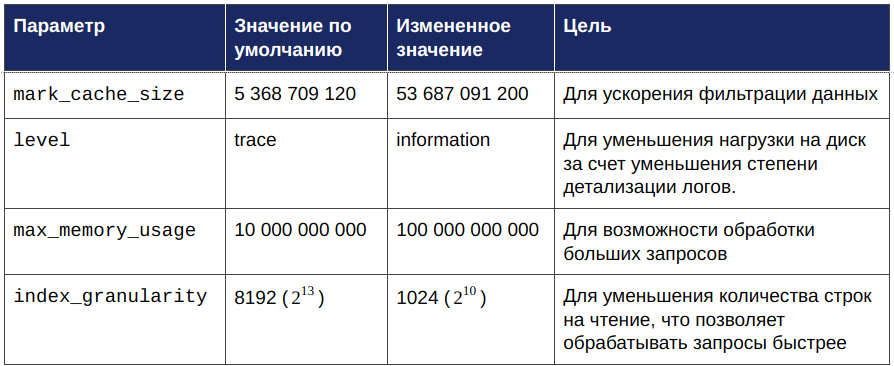
Тестирование производительности в случае неконкурентного запроса
Обращение к неагрегированным данным
Схема данных
Используя данные из сервиса учета ресурсов, в ClickHouse была создана таблица “bill” с помощью следующего запроса:
CREATE TABLE bill (
ts DateTime,
account_id UUID,
domain_id UUID,
metric_name String,
metric_type Enum8('gauge' = 0, 'counter' = 1),
count Int64,
cost Decimal64(8),
service_offering_id UUID,
disk_offering_id UUID,
virtual_machine_id UUID,
network_id UUID
)
ENGINE = MergeTree()
ORDER BY (
ts,
domain_id,
account_id,
metric_name
)
PARTITION BY toYYYYMM(ts)
SETTINGS index_granularity = 1024;
Таким образом, таблица “bill” имеет следующий вид:
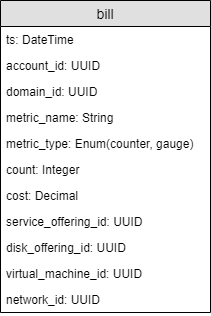
Для каждого из рассматриваемых сценариев были сформированы SQL-запросы к данной таблице, общая схема которых представлена ниже:
Сценарий 1:
SELECT account_id, SUM(cost)
FROM bill
PREWHERE ts >= '<START_DATE>'
AND ts < '<END_DATE>'
GROUP BY account_id
Сценарий 2A:
SELECT period, metric_name, sum(cost)
FROM bill
PREWHERE ts >= '<START_DATE>'
AND ts < '<END_DATE>'
AND domain_id = '<DOMAIN_ID>'
AND account_id = '<ACCOUNT_ID>'
GROUP BY toStartOfHour(ts) AS period, metric_name
Сценарий 2B:
SELECT period, service_offering_id, avg(count), sum(cost)
FROM bill
PREWHERE ts >= '<START_DATE>'
AND ts < '<END_DATE>'
AND domain_id = '<DOMAIN_ID>'
AND account_id = '<ACCOUNT_ID>'
AND metric_name = '<METRIC_NAME>'
GROUP BY toStartOfHour(ts) AS period, service_offering_id
Критический критерий применимости – производительность обработки данных, поэтому мы провели замеры по импорту данных в ClickHouse и скорости обработки одного запроса на выборку данных.
Тестирование добавления данных
Время, которое потребовалось на вставку 1 батча, содержащего 1 млн строк, составило 1,58 секунды, что гораздо меньше предельно допустимого значения, равного 1 минуте.
Тестирование выборки данных
Результаты тестирования скорости обработки одного запроса по каждому из сценариев с использованием ClickHouse представлены в следующей таблице:
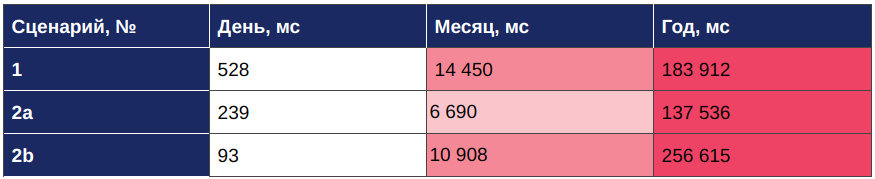
Из таблицы видно, что при обращении к данным среднее время обработки одного запроса удовлетворительно (меньше одной секунды) только при запросе данных за 1 день.
Использование агрегированных данных
Схема данных
Поскольку время получения ответа на запрос не являлось удовлетворительным, было решено задействовать материализованные представления ClickHouse. Были созданы два материализованных представления на основе исходной таблицы “bill”, которые автоматически обновляются при изменении данных в исходной таблице.
Материализованные представления хранят данные, преобразованные соответствующим запросом SELECT. При вставке данных в таблицу “bill” вставляемые данные преобразовываются в соответствии с запросом SELECT, и полученный результат добавляется в материализованное представление.
CREATE MATERIALIZED VIEW bill_hourly
ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(ts_hour)
ORDER BY (
ts_hour,
domain_id,
account_id,
metric_type,
metric_name,
service_offering_id,
disk_offering_id,
virtual_machine_id,
network_id
)
SETTINGS index_granularity = 1024
AS SELECT
ts_hour,
account_id,
domain_id,
metric_name,
metric_type,
sumIf(count, metric_type = 'counter') AS sum_count,
avgIfState(count, metric_type = 'gauge') AS avg_count,
sum(cost) AS cost,
service_offering_id,
disk_offering_id,
virtual_machine_id,
network_id
FROM bill
GROUP BY
toStartOfHour(ts) AS ts_hour,
account_id,
domain_id,
metric_name,
metric_type,
service_offering_id,
disk_offering_id,
virtual_machine_id,
network_id;
CREATE MATERIALIZED VIEW bill_daily
ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(ts_date)
ORDER BY (
ts_date,
domain_id,
account_id,
metric_type,
metric_name,
service_offering_id,
disk_offering_id,
virtual_machine_id,
network_id
)
SETTINGS index_granularity = 1024
AS SELECT
ts_date,
account_id,
domain_id,
metric_name,
metric_type,
sumIf(count, metric_type = 'counter') AS sum_count,
avgIfState(count, metric_type = 'gauge') AS avg_count,
sum(cost) AS cost,
service_offering_id,
disk_offering_id,
virtual_machine_id,
network_id
FROM bill
GROUP BY
toDate(ts) AS ts_date,
account_id,
domain_id,
metric_name,
metric_type,
service_offering_id,
disk_offering_id,
virtual_machine_id,
network_id;
Представления “bill_hourly” и “bill_daily” содержат данные, агрегированные по часам и дням соответственно, и имеют следующий вид:
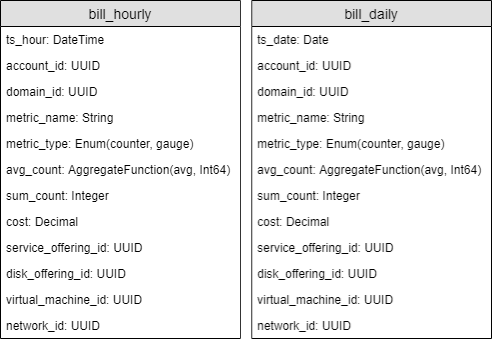
Тестирование добавления данных
При наличии двух материализованных представлений, время вставки 1 батча, содержащего 1 млн строк, увеличилось с 1,58 до 2,12 секунды, что не превышает предельного значения, равного 1 минуте.
Для того чтобы оценить, как количество материализованных представлений (MV) влияет на время вставки данных, мы провели эксперимент, в рамках которого сравнили время вставки одного батча, содержащего 10 млн строк, в таблицу без MV с временами вставки в таблицу при наличии материализованных представлений. Результаты эксперимента представлены в следующей таблице.

В нашем случае, каждое MV, содержащее дополнительную агрегацию данных добавило примерно 3 секунды к первоначальному времени вставки.
Кроме того, на данном тесте мы проверяли атомарность обновления данных во всех структурах – как в основной таблице, так и в MV. Опыт показал, что операция вставки завершается только после обновления всех структур, при этом до завершения операции новые данные недоступны как в основной таблице, так и MV.
Тестирование выборки данных
Для получения данных за 1 день с разбивкой по часам мы использовали материализованное представление “bill_hourly”, а в двух других случаях (за месяц и за год) – “bill_daily”, где данные сгруппированы по дням. Результаты тестирования представлены в следующей таблице:
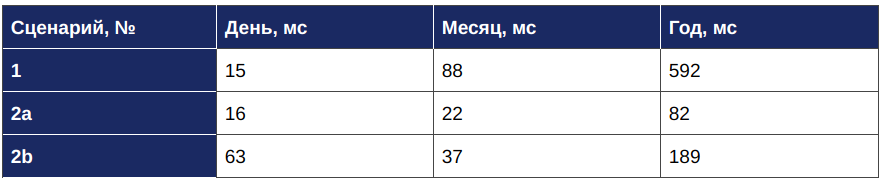
Из данных таблицы 7 следует, что время обработки запроса по каждому из сценариев не превышает максимально допустимого в рамках задачи значения (1 секунды).
Тестирование производительности в случае конкурентных запросов
Для анализа производительности базы данных при ожидаемой нагрузке в 10 000 пользователей мы провели нагрузочное тестирование и рассчитали среднее значение времени ответа (в секундах) при одновременной обработке 10, 20, 50 и 100 запросов. Нагрузочное тестирование было проведено для второго сценария за один день и за один месяц, поскольку в рамках нашего проекта предполагается, что именно эти запросы будут выполняться конкурентно пользователями системы. Результаты нагрузочного тестирования представлены на графиках 2-5.
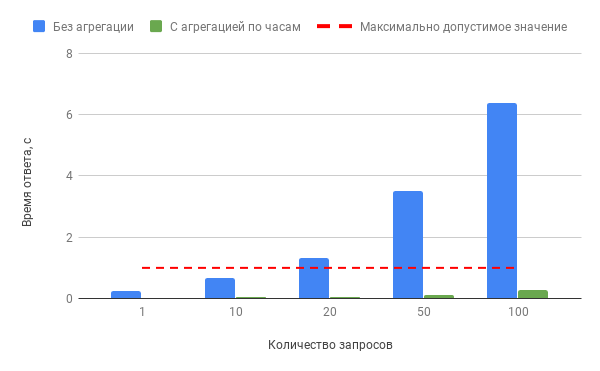
Производительность БД при конкурентных запросах к “bill” и “bill_hourly” по сценарию 2A за 1 день:
Производительность БД при конкурентных запросах к “bill” и “bill_hourly” по сценарию 2B за 1 день:
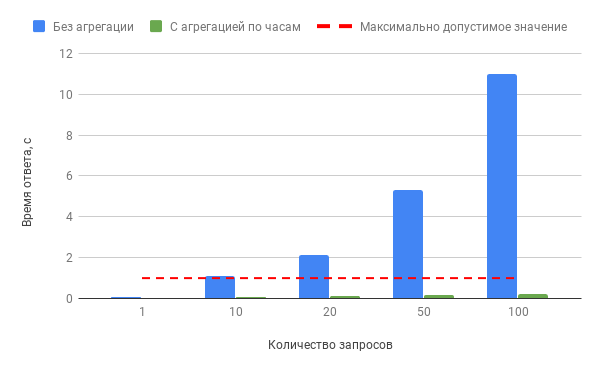
Из графиков видно, что в случае обращения к неагрегированным данным уже при 10 одновременных запросах время ответа превышает установленный максимум в 1 секунду. В случае использования материализованного представления время ответа не превышает 0,3 секунды при 100 одновременных запросах данных.
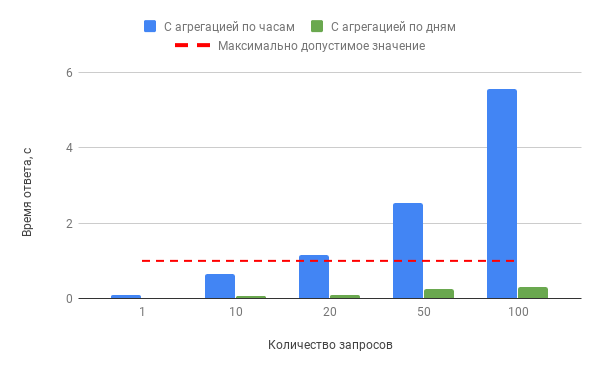
Производительность БД при конкурентных запросах к “bill_hourly” и “bill_daily” по сценарию 2a за 1 месяц:
Производительность БД при конкурентных запросах к “bill_hourly” и “bill_daily” по сценарию 2b за 1 месяц:
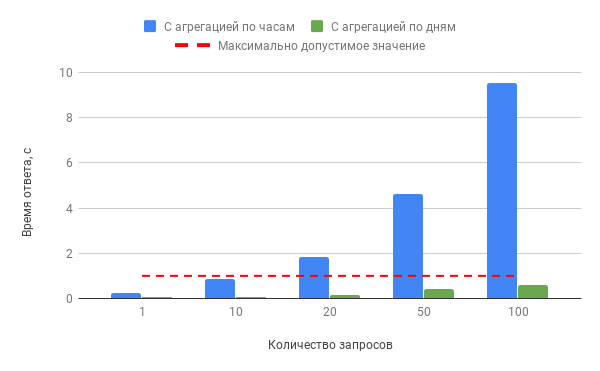
Из графиков видно, что использование материализованного представления с агрегацией по часам при запросе данных за 1 месяц является допустимым при 10 одновременных запросах, однако при 20, 50 и 100 запросах время ответа может достигать 9,5 секунд. Использование представления bill_daily” позволяет решить проблему, сокращая время обработки запроса до 0,6 секунды.
Заключение
Результаты тестирования ClickHouse в рамках задачи проектирования системы биллинга показали, что исходные требования по скорости обработки запросов выполняются при обращении к объектам, содержащим агрегированные данные. При наличии материализованных представлений также выполняются требования по атомарности и скорости вставки данных.
Стоит отметить, что материализованные представления ClickHouse содержат довольно много открытых багов. В процессе тестирования мы также столкнулись с одним из них: при определении use_uncompressed_cache = 1 в конфигурационном файле ClickHouse для использования кэша несжатых блоков сервер падал с ошибкой “segmentation fault” на повторном запросе к материализованному представлению. Кроме того, среди них есть и открытая ошибка о расхождении результатов одних и тех же запросов, полученных через различные материализованные представления.
ClickHouse – отличный продукт, который возможно использовать в качестве аналитической базы данных. Однако при анализе применимости необходимо произвести тщательное тестирование, чтобы убедиться в том, что в рамках требуемых вариантов использования, СУБД обеспечивает необходимую производительность и не имеет ошибок в работе.
В рамках решаемой нами задачи мы протестировали еще ряд СУБД (Apache Hive, Apache Cassandra, SnappyData, Greenplum, MonetDB, ScyllaDB). Однако все они продемонстрировали худшую применимость в рамках требований задачи.
В конечном итоге мы отклонили все продукты для хранения и аналитической обработки больших данных, решив использовать для реализации кластерные вычисления в памяти с помощью Apache Ignite и его механизма Durable Memory. На выбор повлияли дополнительные требования, которые мы видим вероятными в будущем: мы поняли, что нам важно обеспечить гибкую обработку данных, основанную как при декларативных, так и при императивных способах обработки, что неэффективно при использовании внешних СУБД.