OpenCV – популярный фреймворк, который широко используется при разработке продуктов для интеллектуальной видеоаналитики. Такие решения опираются как на классические алгоритмы компьютерного зрения, например, алгоритм определения оптического потока, так и на алгоритмы, использующие современный инструментарий искусственного интеллекта, в частности, нейронные сети.
Большая часть алгоритмов является ресурсоемкой, что, в зависимости от целей обработки, может требовать большого объема вычислительных ресурсов, для обработки даже одного видеопотока в режиме реального времени. Под ресурсами подразумеваются как вычислительные ядра CPU, так и GPU, а так же другие аппаратные ускорители.
Камера или другой источник поставляет видеопоток с определенным количеством кадров в секунду (FPS, Frames Per Second), которые должны быть обработаны аналитической платформой. Каждый кадр видео занимает существенный объем памяти, например, для кадра разрешения 4K глубиной цвета 24 бит, массив NumPy ndarray будет занимать 24 MB в RAM, а за 1 секунду буферизации при FPS равным 30, данных кадров накопится на 729 MB. При низкой производительности цепочки обработки можно столкнуться с ситуацией отказа из-за переполнения RAM, дискового пространства или потери кадров. Таким образом, цепочка обработки должна быть достаточно производительной, чтобы успеть обработать все кадры.
Базовое решение
Простой подход к построению цепочки обработки подразумевает, что она является последовательной. В этом случае, при стандартной частоте кадров равной 30, цепочка должна обрабатывать каждый кадр за 1/30 секунды (33 мс). Если вам удается добиться такой производительности цепочки, можно не искать более производительную архитектуру, а остановиться на данной схеме. Базовый пример из OpenCV как раз успешно обрабатыват кадр за 1/30 секунды на любом актуальном оборудовании:
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
# Our operations on the frame come here
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Display the resulting frame
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
В том случае, если цепочка успешно обрабатывается линейно в рамках одного процесса, масштабирование тривиально – вы просто добавляете вычислительные ресурсы и балансируете запуск цепочек обработки таким образом, чтобы не создавать перегрузку CPU, GPU или аппаратных ускорителей.
Часто, однако, время работы цепочки подвержено колебаниям, которые зависят от количества анализируемых объектов и событий, происходящих в кадре. Таким образом, время работы цепочки может варьироваться в довольно широких пределах, к примеру, в нашем программном решении по распознаванию лиц в кадре один из этапов занимает следующее время на устройстве Nvidia Jetson Xavier:
- одно лицо в кадре:
2.4 ± 0.18 мс; - пять лиц:
10.01 ± 0.44 мс.
Как видно, время линейно растет относительно количества лиц. Это пример алгоритма, время выполнения которого зависит от содержимого кадра. Если таких алгоритмов несколько, время обработки кадра может выходить за пределы желаемого, что приведет к задержке обработки или потере кадров. В итоге, возникает потребность распределения и декомпозиции работы между вычислителями, в рамках которой реализуется распределенный граф обработки, где каждый узел обеспечивает обработку некоторой части общего алгоритма.
Например, каждое из пяти найденных в кадре лиц может быть обработано на отдельном узле за 2.4 мс, при этом сам граф может внести фиксированную задержку за счет затрат на пересылку данных между его узлами.
Шаблон ZeroMQ Push-Pull для построения масштабируемой архитектуры
ZeroMQ является высокопроизводительной шиной обмена данными поверх стандартных сетевых сокетов (сокеты на стероидах), которая реализует ряд паттернов для распределенной обработки. Паттерн push-pull хорошо подходит для решения задачи масштабирования цепочки обработки реального времени, которая характерна для задачи. В документации ZeroMQ паттерн демонстрируется следующей картинкой:
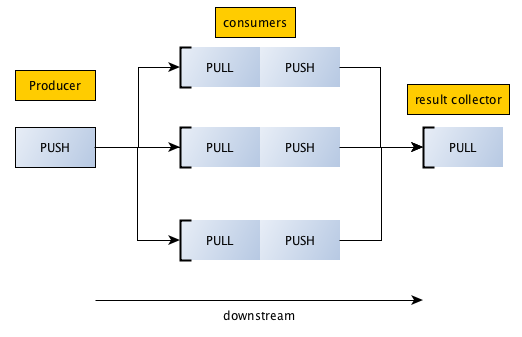
Данные движутся слева направо, чем-то напоминая шаблон MapReduce, который используется при обработке больших данных. При этом средняя часть (consumers) может масштабироваться.
Стоит заметить, что цепочку можно продлить дальше, используя специальные “устройства” ZeroMQ. Для данного паттерна должно использоваться устройство Streamer. В этой статье мы не будем рассматривать данную возможность ZeroMQ.
Реализация цепочки с помощью ZeroMQ
Рассмотрим, как можно реализовать цепочку обработки, приведенную в примере выше с помощью ZeroMQ, чтобы сделать ее масштабируемой. Для этого “разрежем” ее на 3 части:
- декодер видео;
- обработчик BGR → Gray;
- визуализатор.
Декодер видео
Декодер выглядит предельно просто: видео разбирается на кадры, которые передаются через push-pull в обработчик. Пока ни одного обработчика не зарегистрировано, декодер будет находиться в заблокированном состоянии. Работать он начнет тогда, когда появится хотя бы один обработчик, который присоединится к нему. При наличии нескольких обработчиков, декодер будет равномерно распределять кадры между ними. В данном примере для подсчета задержки видео передается с дополнительной временной меткой.
В примере используется камера, которая генерирует видеопоток
640x480@30FPS.
import cv2
import zmq
from time import time
cap = cv2.VideoCapture(0)
context = zmq.Context()
dst = context.socket(zmq.PUSH)
dst.bind("tcp://127.0.0.1:5557")
while True:
ret, frame = cap.read()
dst.send_pyobj(dict(frame=frame, ts=time()))
Обработчик BGR → Gray
Обработчик получает фрейм, преобразует его в гамму серого цвета и отправляет дальше по цепочке визуализатору. Вы можете запустить множество обработчиков, при этом они будут равномерно распределять поступающую нагрузку между собой. Таким образом можно масштабировать цепочку горизонтально, а время обработки каждого кадра перестает быть критическим параметром.
import cv2
import zmq
from time import time
context = zmq.Context()
src = context.socket(zmq.PULL)
src.connect("tcp://127.0.0.1:5557")
dst = context.socket(zmq.PUSH)
dst.connect("tcp://127.0.0.1:5558")
count = 0
delay = 0.0
while True:
msg = src.recv_pyobj()
ts = msg['ts']
frame = msg['frame']
tnow = time()
count += 1
delay += tnow - ts
if count % 150 == 0:
print(delay/count)
delay = 0.0
count = 0
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
dst.send_pyobj(gray)
Визуализатор
Визуализатор отображает поступающие фреймы в окне.
import cv2
import zmq
context = zmq.Context()
zmq_socket = context.socket(zmq.PULL)
zmq_socket.bind("tcp://127.0.0.1:5558")
while True:
frame = zmq_socket.recv_pyobj()
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
В ходе экспериментов на ноутбуке с CPU i5-6440HQ задержка шага декодер → обработчик на интерфейсе локальной петли составляет порядка 4 мс (640x480@30FPS):
0.004144287109375
0.003949470520019531
0.004002218246459961
0.0038284858067830405
0.003976351420084636
0.004110925992329915
0.004024415016174316
0.003885181744893392
0.0037894550959269207
0.003757945696512858
Таким образом, вся цепочка декодер → обработчик → визуализатор вносит задержку обработки около 8-9 мс.
На что необходимо обратить внимание
Многоузловая схема. При реализации многоузловой схемы необходимо использовать маршрутизируемые адрес. Обратите внимание, что метод bind используется только в декодере и визуализаторе, в то время, как в обработчик использует метод connect, что позволяет масштабировать количество обработчиков.
Также, при использовании маршрутизируемых сетевых адресов задержка может отличаться от той, которая получена на интерфейсе локальной петли, что будет зависеть как от настроек программного стека операционной системы, так и от используемого сетевого оборудования.
Пропускная способность сети. Как было ранее показано, передача 4K видео между декодером и обработчиками требует пропускную способность равную 6 Gbit/s, то есть, канал связи производительностью 1 Gbit/s не подойдет, требуется использовать сеть 10 Gbit/s и производительнее. Для реального масштабируемого варианта стоит рассмотреть 40 Gbit/s и более производительные сетевые стеки или выполнять уменьшение разрешения видеопотока до распределения между обработчиками. Альтернативный подход заключается в сжатии передаваемых фреймов с помощью быстрых компрессионных алгоритмов, например, LZ4, что может сократить затраты канальной емкости, но внесет дополнительную задержку в работу цепочки.
Затраты на шифрование. Если вы используете ZeroMQ с шифрованием данных, стоит учесть вклад криптографических вычислений, поскольку они могут добавить как дополнительную задержку, так и затраты CPU узлов.
Гарантированная обработка. ZeroMQ не содержит выделенного брокера, который бы обеспечивал возможность повторной обработки. В случае, если требуется гарантированно обработать все кадры, стоит обратиться к архитектуре, которая поддерживает такую модель, например, использовать брокер сообщений RabbitMQ или Apache Kafka.
Запуск без этапа визуализатора. В случае, если объединение результатов обработки не требуется, то цепочку можно сократить до двух этапов: декодер → обработчик.
Обработка зависимых кадров. Приведенная модель параллелизации подразумевает, что кадры обрабатываются независимо, если логика обработки будущих кадров зависит от обработки предыдущих, требуется использовать иные механизмы ускорения обработки.